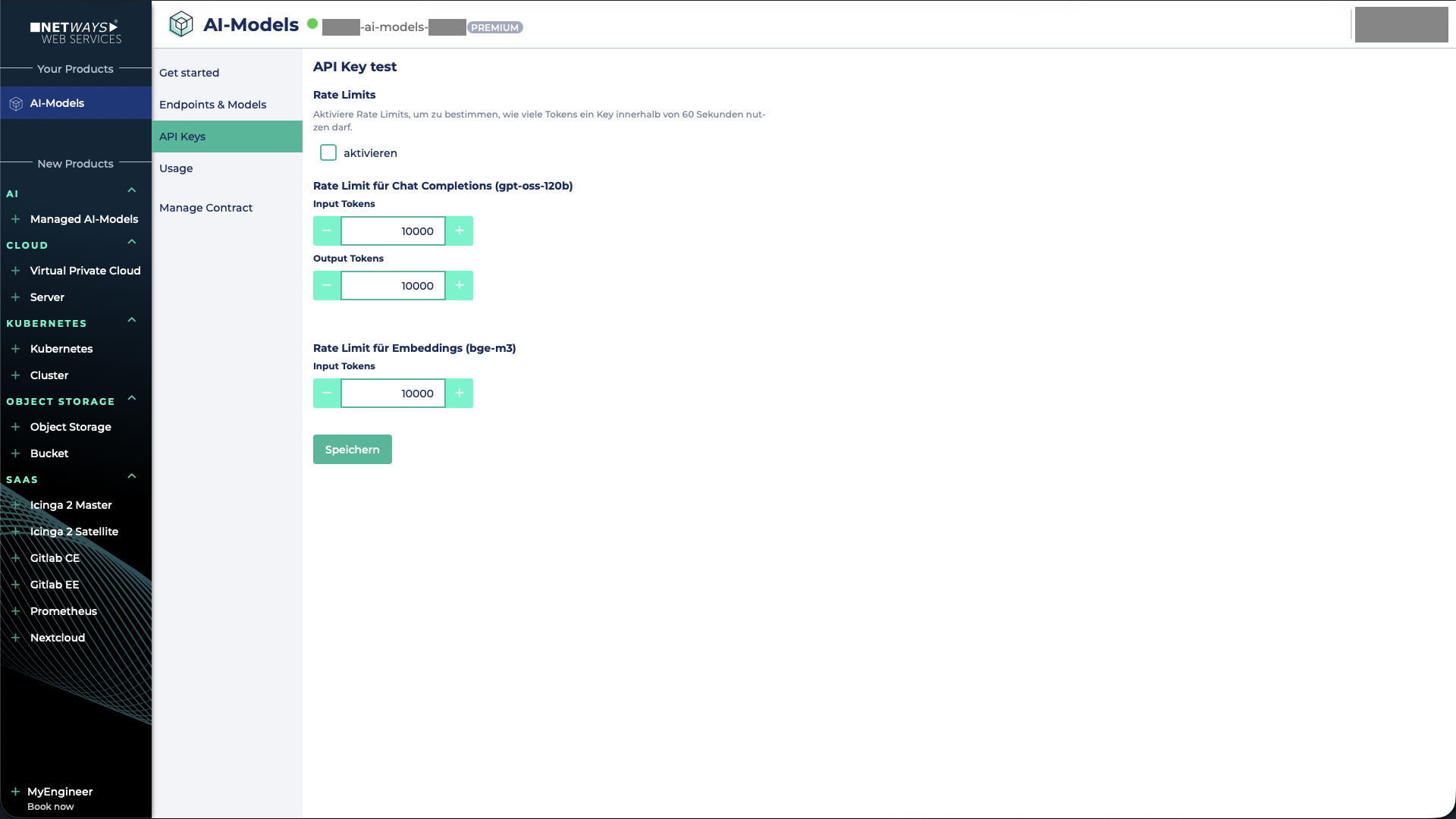
Rate Limiting
Es besteht die Möglichkeit, Rate Limits für Modelle zu definieren. Diese können entweder global für alle API-Keys oder individuell pro API-Key festgelegt werden.
Das Rate Limit bestimmt, wie viele Tokens innerhalb eines Zeitraums von 60 Sekunden verarbeitet werden dürfen. Wird ein globales Rate Limit definiert, gilt dieses automatisch auch für neu erstellte API-Keys.
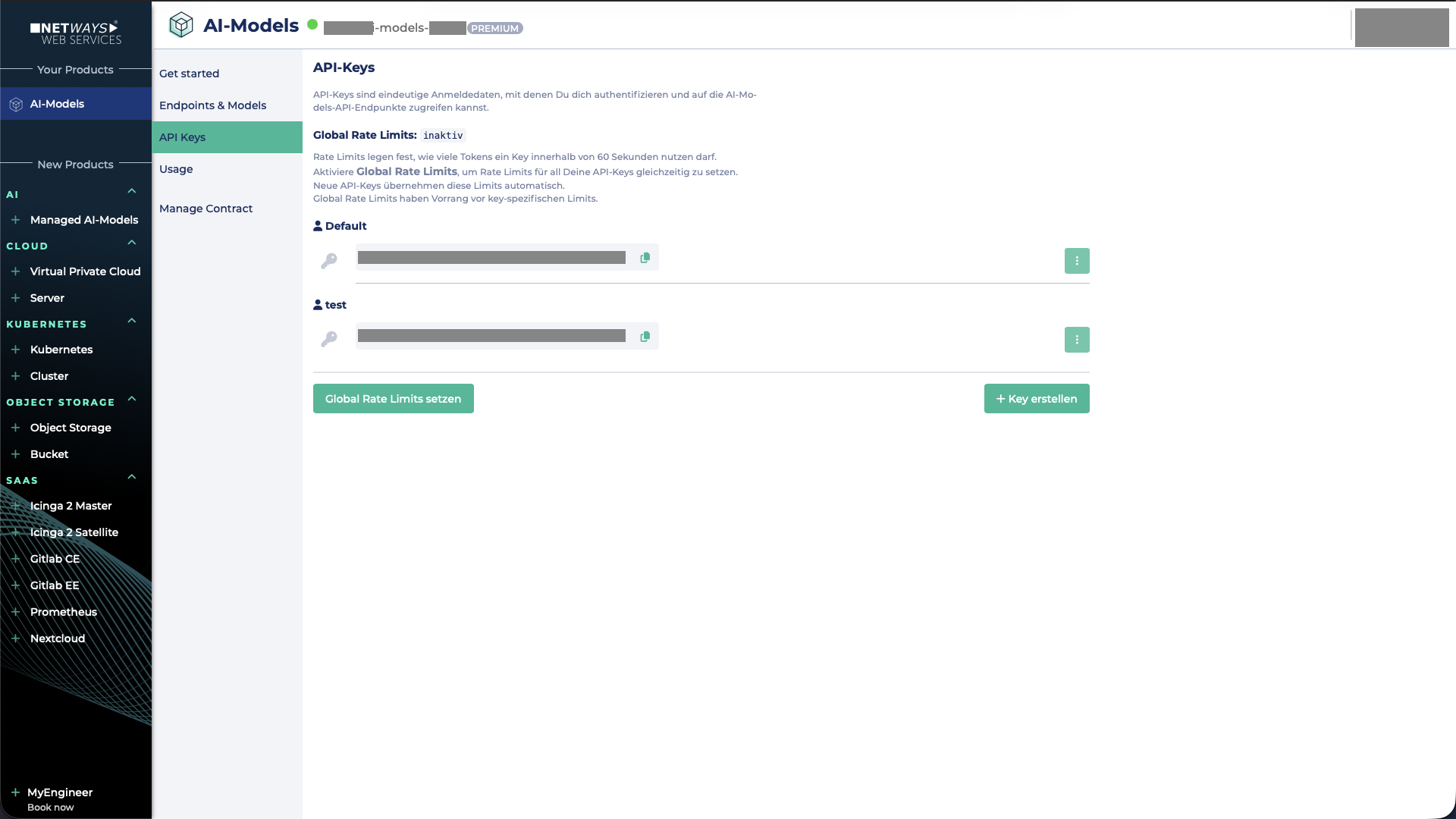
Globales Rate Limit setzen
Zunächst muss zum Reiter API Keys navigiert werden. Dort befindet sich der Button Global Rate Limits setzen.
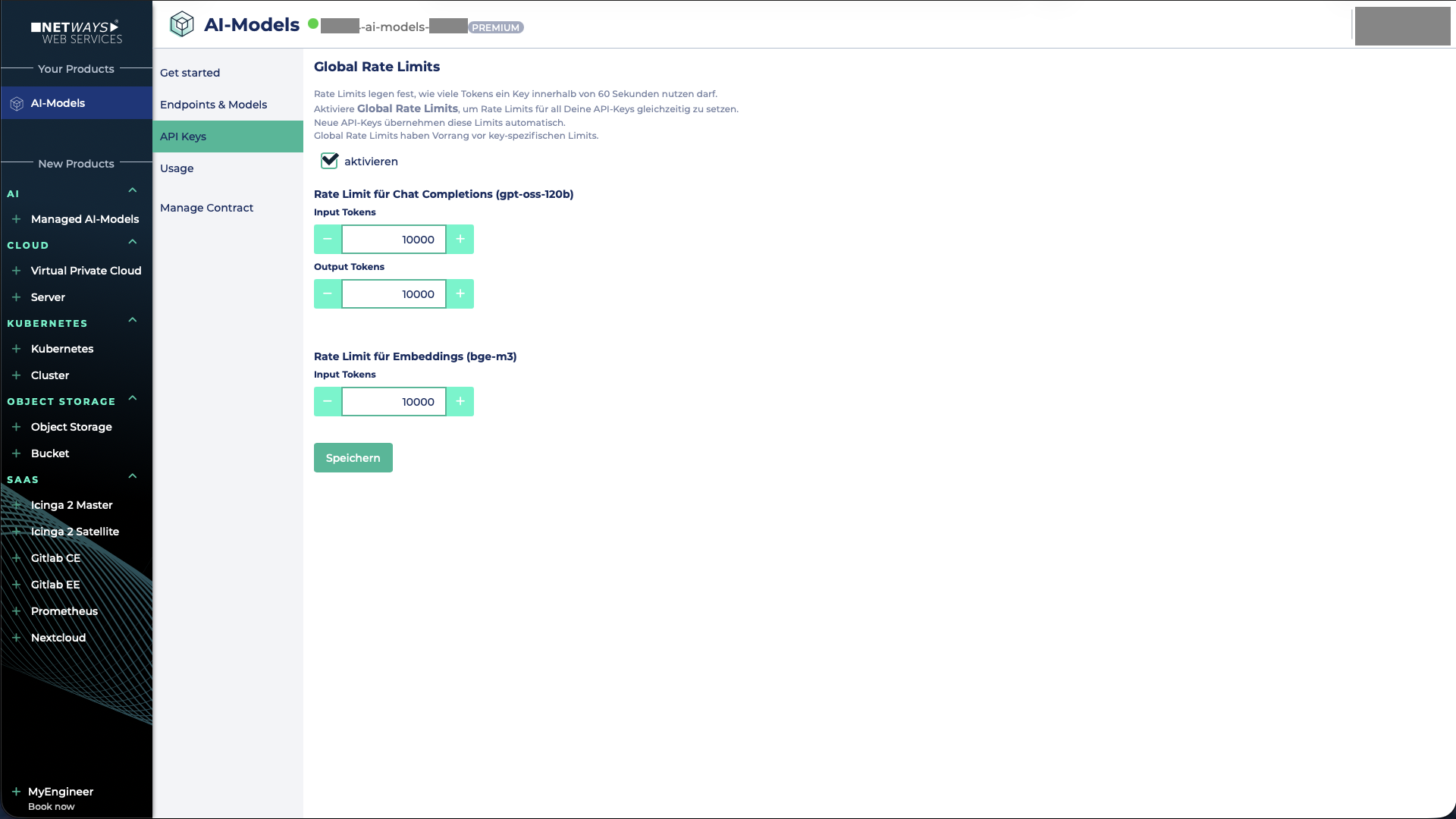
Um das Rate Limit zu aktivieren, muss die entsprechende Checkbox ausgewählt werden.
Anschließend können für das Modell gpt-oss-120b sowohl das Input- als auch das Output-Token-Limit festgelegt werden.
Für das Embedding-Modell bge-m3 kann ausschließlich ein Input-Token-Limit definiert werden, da dieses Modell keine Output-Tokens generiert.
Abschließend müssen die Einstellungen gespeichert werden. Nach kurzer Zeit sind die definierten Limits aktiv.
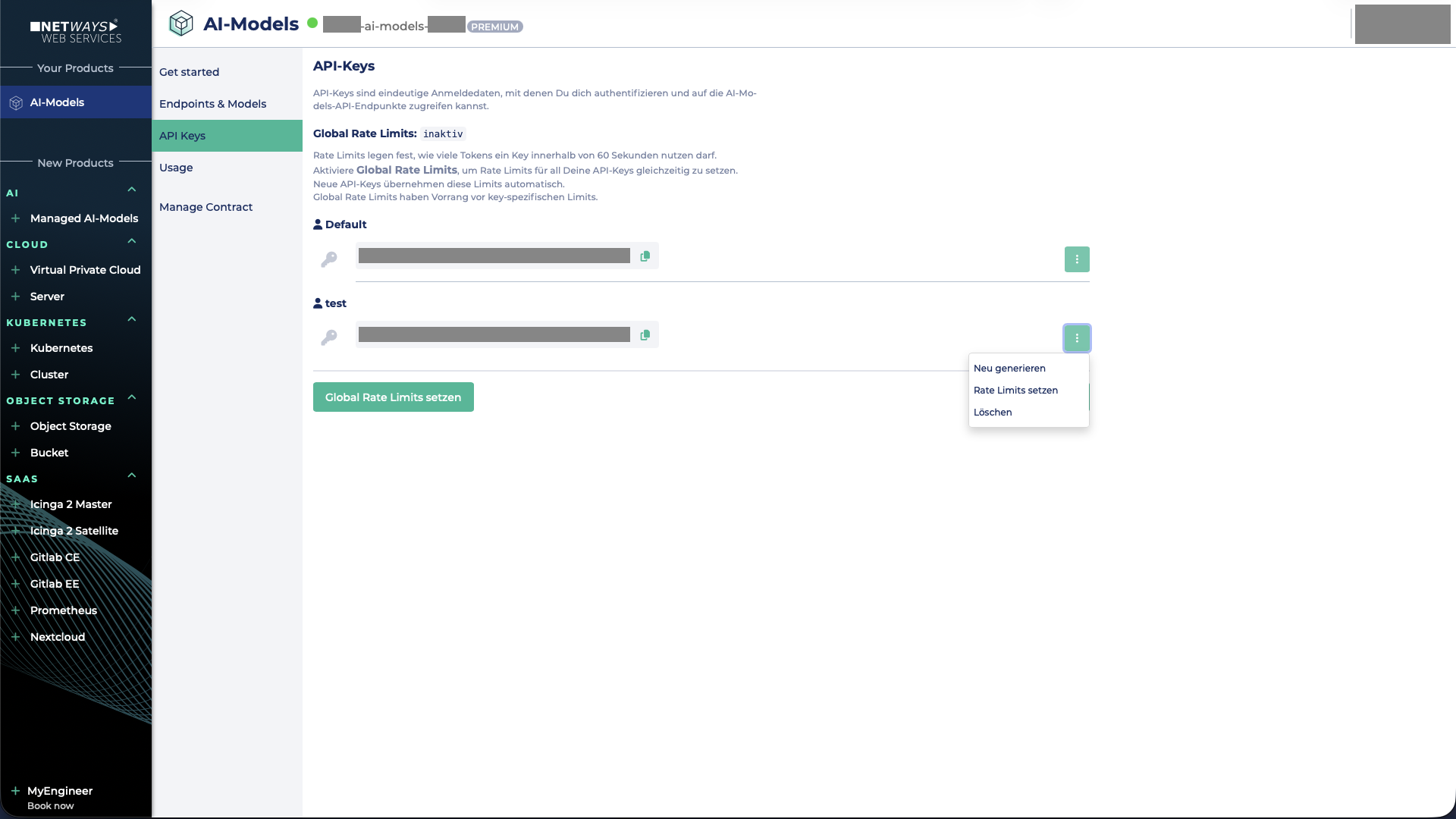
Rate Limit pro API-Key setzen
Um ein Rate Limit für einen einzelnen API-Key zu konfigurieren, muss auf die drei Punkte rechts neben dem jeweiligen API-Key geklickt und anschließend Rate Limits setzen ausgewählt werden.
Hinweis
Ein globales Rate Limit überschreibt bestehende Rate Limits für einzelne API-Keys!
Anschließend können für das Modell gpt-oss-120b sowohl das Input- als auch das Output-Token-Limit festgelegt werden.
Für das Embedding-Modell bge-m3 kann ausschließlich ein Input-Token-Limit definiert werden, da keine Output-Tokens erzeugt werden.
Nach dem Speichern der Einstellungen werden die Limits nach kurzer Zeit wirksam.