Fedora CoreOS Upgrades
| v1.29 | v1.30 | v1.31 | v1.32 | v1.33 | v1.34 | |
|---|---|---|---|---|---|---|
| Fedora CoreOS | 40,41 | 41,42 | 41,42 | 41,42 | 42,43 | 42,43 |
Um automatische OS Upgrades für Nodes eines NETWAYS Managed Kubernetes Clusters zu konfigurieren, klickt man im Kontextmenü des Clusters auf Update Operating System.
Dabei gibt es mehrere Möglichkeiten des Update-Verfahrens. Zur Auswahl stehen Immediate, Periodic oder Lock-based. Jede Option hat andere Vorteile. Generell empfehlen wir jedoch die Nutzung der Lock-based Upgradestrategie. Im Folgenden werden die einzelnen Option nochmal erklärt. In jedem Fall sind die Versionen von Fedora CoreOS an die von Kubernetes gekoppelt. Die letzen beiden supporteten Versionen von CoreOS befinden sich in der obigen Tabelle.
Node Restarts während OS Upgrades
Cluster-Nodes werden bei OS Upgrade automatisch neugestartet. Dies ist bei der Planung von Upgrades zu bedenken.
Kubernetes Upgrades
Damit Kubernetes Upgrades durchgeführt werden können, muss zwingend eine aktuelle Version von Fedora CoreOS laufen. Dabei reicht eine der letzten beiden Versionen. Diese kann man der vorhergehenden Tabelle entnehmen. Eine jede Nodegroup ist dabei an ihre erstmalig gestartete CoreOS Version gebunden.
Hat man also eine Nodegroup für v1.24 gestartet, werden neue Nodes immer in der alten Fedora CoreOS Version 37 gestartet. Daher ist es sinnvoll Nodegroups häufiger gegen neue zu ersetzen. Das kann gut in den Kubernetes Upgrade Prozess eingebunden werden. Die alte Nodegroup braucht dann nicht in der Kubernetes Version geupgraded werden und die Neue kommt direkt in der neusten CoreOS und Kubernetes Version hoch.
Strategien
Warning
Bei den Periodic und Immediate Update-Strategien kommt es zwangsweise zu Unterbrechungen, da keine Node-Drains durchgeführt werden. Die Nodes sind während des Updates bis zu einer Minute nicht erreichbar.
Lock-based
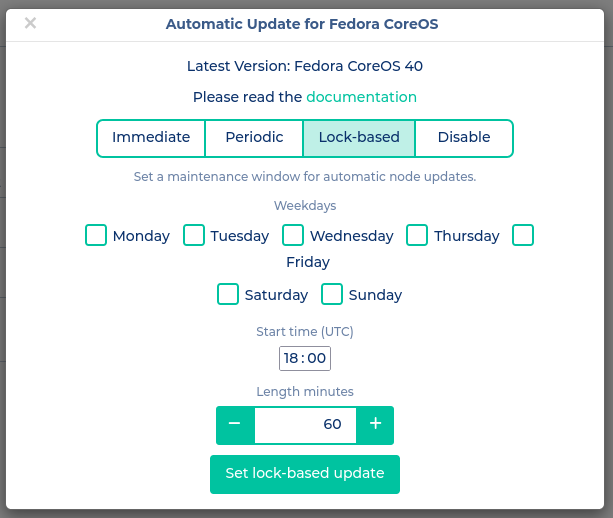
Diese Strategie nutzt für die Orchestrierung der Upgrades fleetlock. Wir haben den Dienst entsprechend erweitert, um eine Zeitspanne anzugeben, in dem die Upgrades geschehen dürfen. Dabei wird immer nur eine Node parallel geupgraded und vor dem finalisierendem Reboot gedrained. Somit bleibt der Impact so klein wie möglich.
Periodic
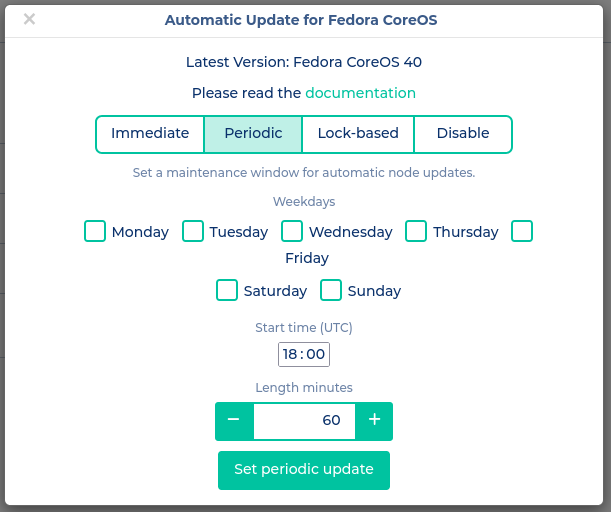
Bei der Nutzung von Periodic Upgrades geschehen diese nur in dem angegebnen Zeitfenster. Dabei werden jedoch, anders als bei den Lock-based Upgrades, keine Drains durchgeführt und Nodes direkt nach der Installation der Upgrades neugestartet. Daher kann es vorkommen, dass mehrere Nodes parallel Upgrades installieren und in der Zeit Dienste im Cluster nicht erreichbar sind. Sollten parallel 2 oder mehr Controlplane nodes in einem HA-Cluster geupdatet werden, wird auch die API beeinträchtigt sein. Da der Reoot jedoch typischerweise in unter einer Minute erledigt ist, hält sich der Impact jedoch in Grenzen. Deshalb sollte aber natürlich darauf geachtet werden, dass das Zeitfenster entsprechend außerhalb der produktiven Zeiten fällt.
Immediate
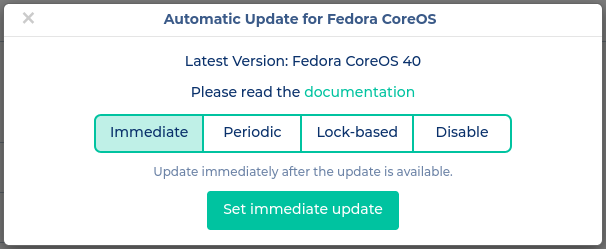
Diese Strategie ist primär für Staging Umgebungen interessant, genauso wie vor Kubernetes Upgrades. Wie der Name bereits vermuten lässt, werden Upgrades direkt eingespielt. Dadurch wird es zur Beeinträchtigen der Dienste im Cluster kommen. Es ist aber dennoch praktisch, um schnellstmöglich auf eine aktuelle Version zu gelangen.