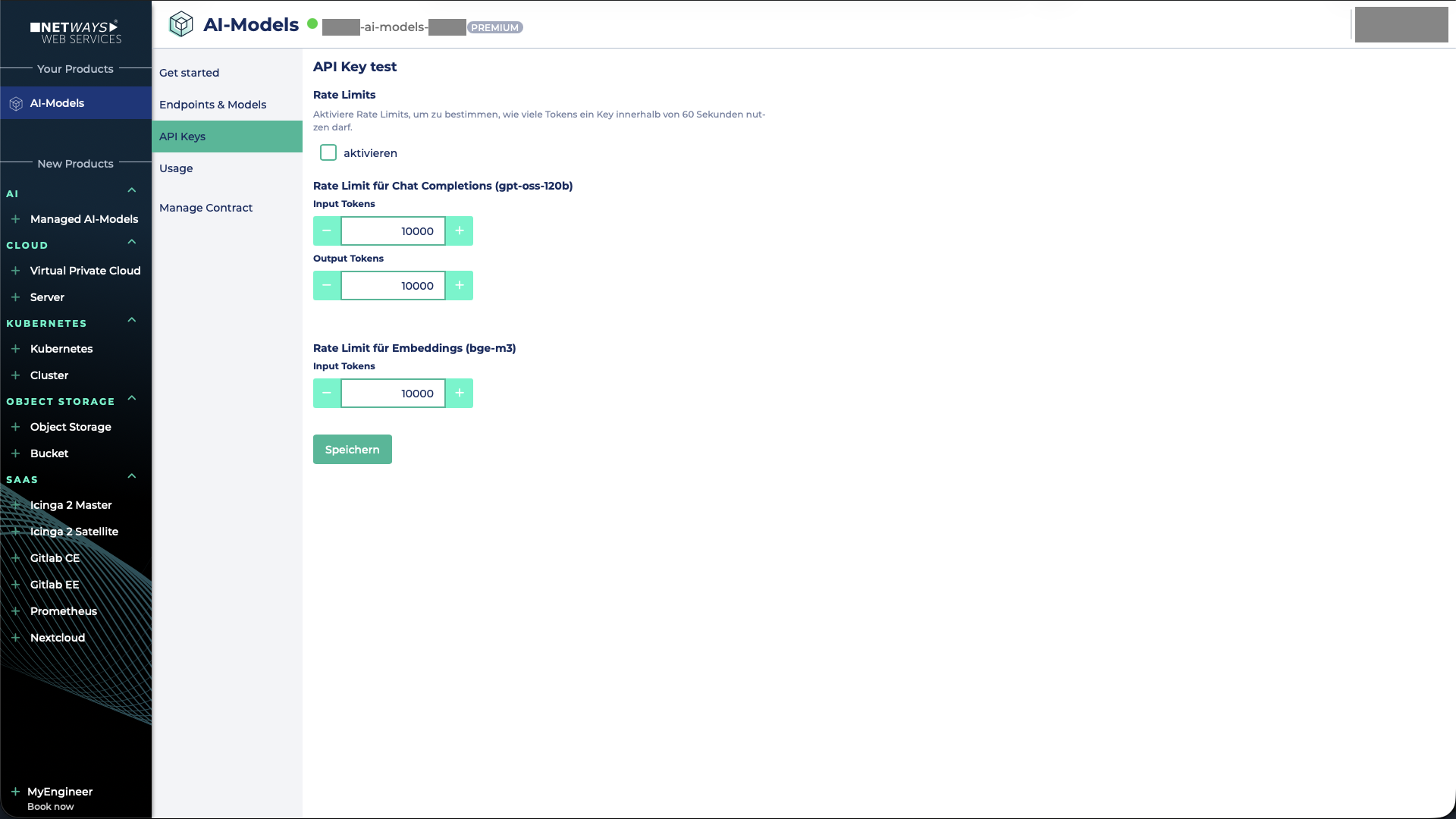
Rate Limiting
In addition, it is possible to define rate limits for models. These can be set either globally for all API keys or individually per API key.
The rate limit determines how many tokens may be processed within a 60‑second window.
If a global rate limit is defined, it automatically applies to newly created API keys as well.
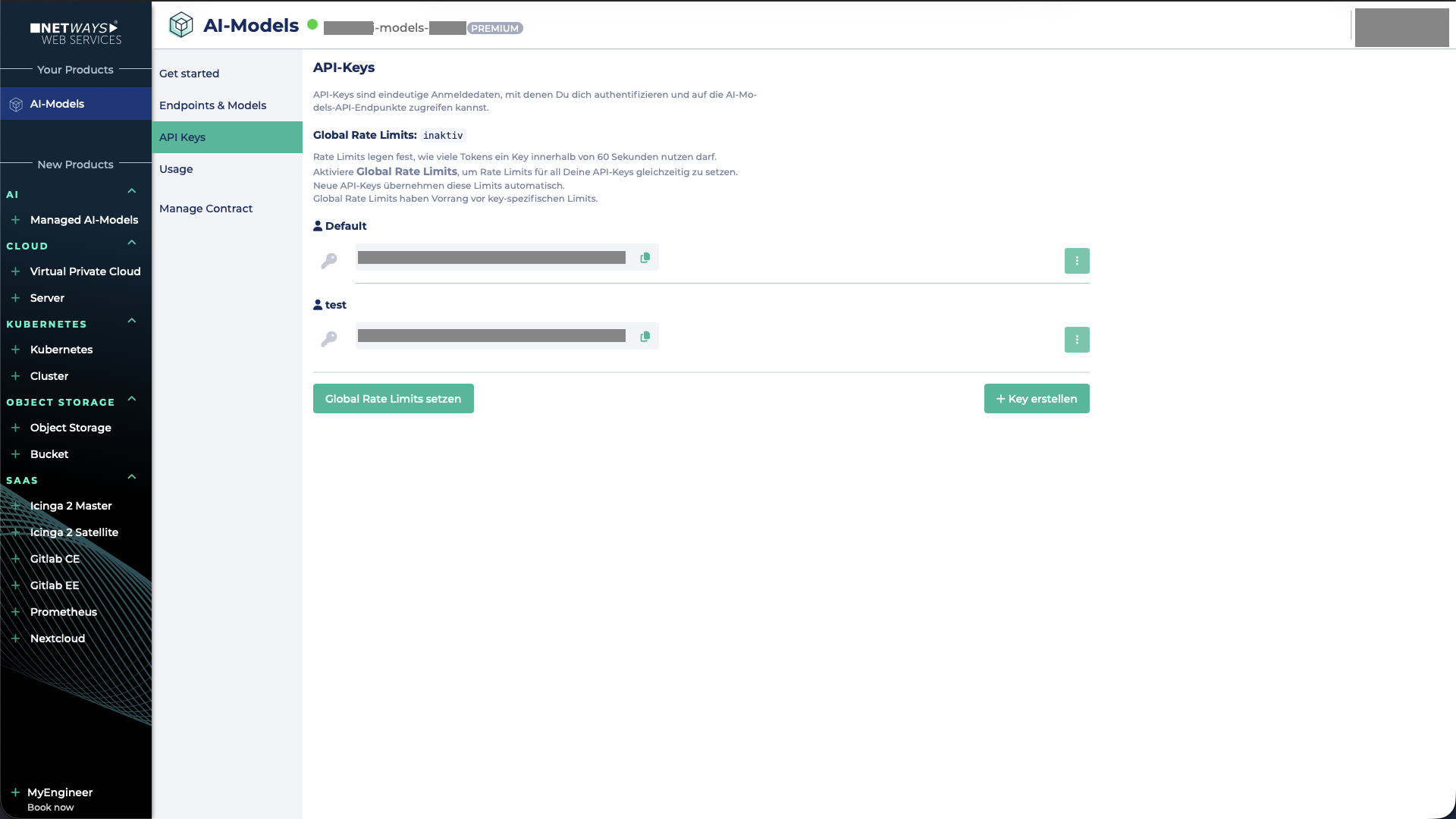
Setting a Global Rate Limit
First, navigate to the API Keys tab. There you will find the button Set Global Rate Limits.
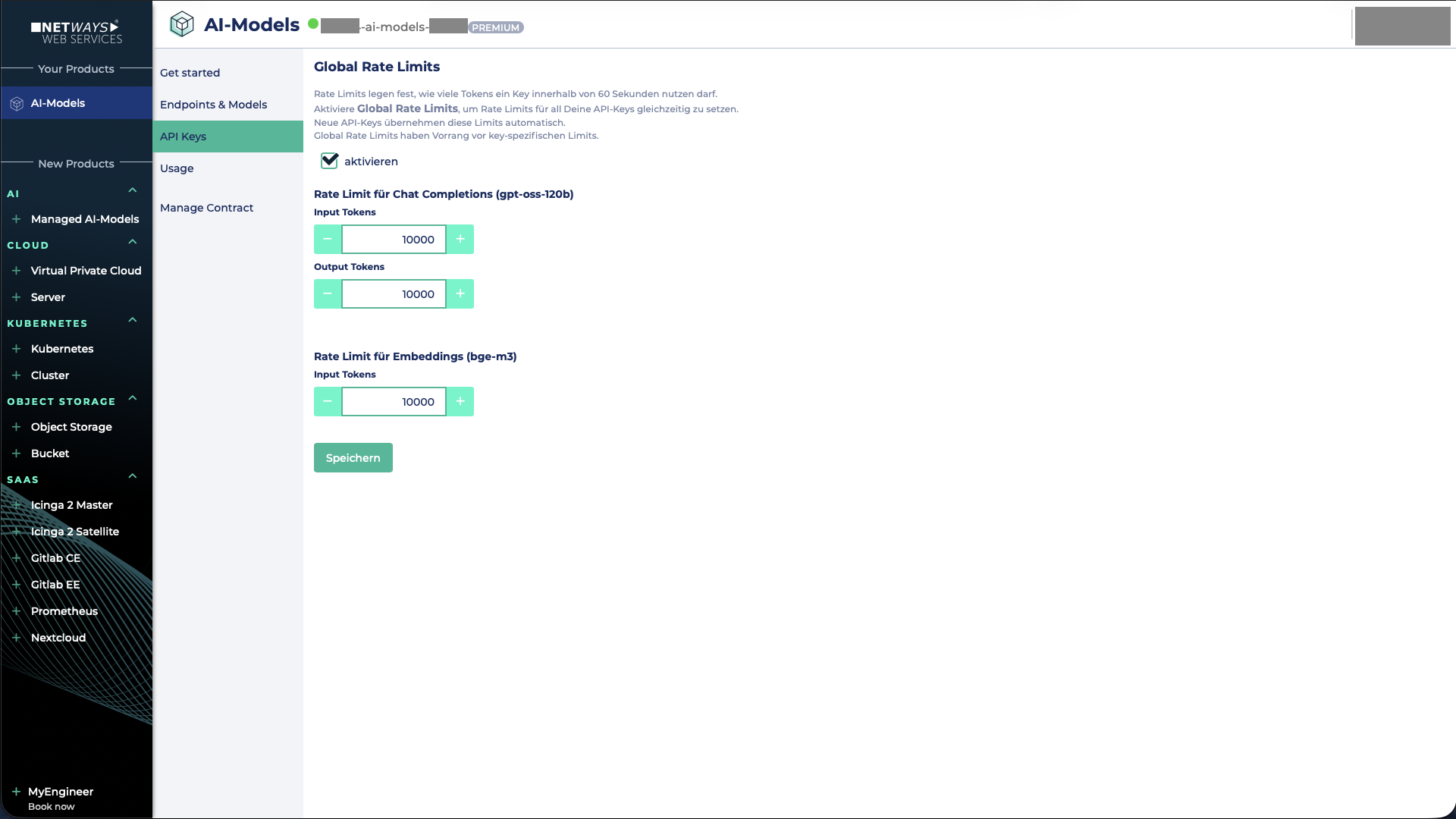
To activate the rate limit, tick the corresponding checkbox.
Then you can specify both the Input‑Token Limit and the Output‑Token Limit for the model gpt-oss-120b
.
For the embedding model bge-m3 you can define only an Input‑Token Limit, because this model does not generate output tokens.
Finally, save the settings. After a short while the defined limits become active.
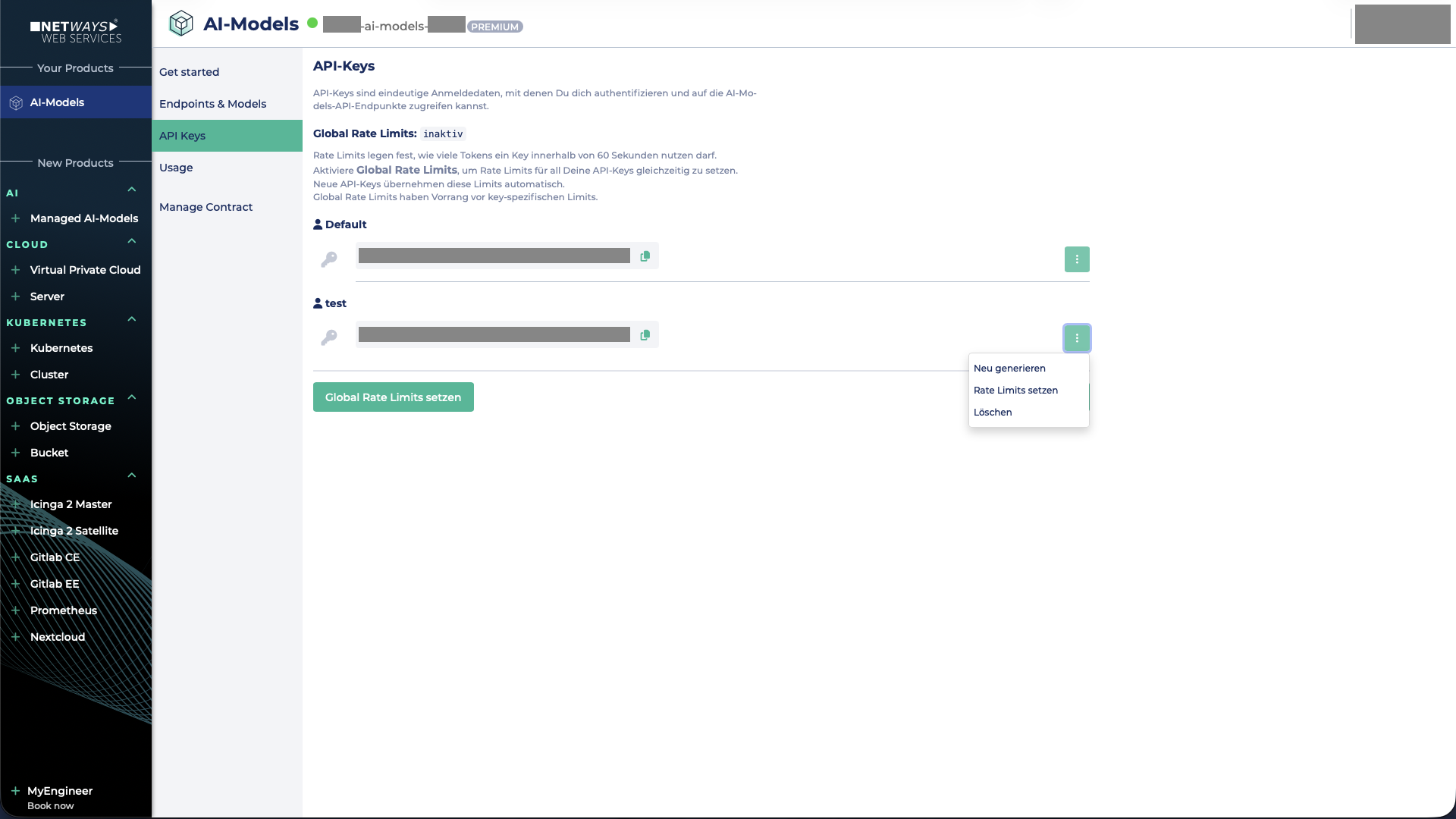
Setting a Rate Limit per API Key
To configure a rate limit for a single API key, click the three dots to the right of the respective API key and then select Set Rate Limits.
Note
A global rate limit overrides any existing rate limits set for individual API keys!
Now you can set both the Input‑Token Limit and the Output‑Token Limit for the model gpt-oss-120b.
For the embedding model bge-m3 you can define only an Input‑Token Limit, since no output tokens are produced.
After saving the settings, the limits take effect after a short period.